Benchmark des modèles de classement
Résultat exploratoire. Meilleure combinaison stable : device_anomaly + extra_trees + random_forest. Elle doit encore être confirmée sur de nouvelles campagnes avant tout pilote opérationnel.
Données et protocole
- Le classeur contient 344 visites, dont 105 fuites confirmées.
- 320 visites sont exploitables par les modèles, dont 99 fuites et 221 non-fuites, issues de 40 campagnes.
- Les 24 visites écartées n'ont pas d'appareil correctement relié ou pas de mesure acoustique le matin concerné. Elles ne sont ni inventées ni complétées artificiellement.
- Caractéristiques calculées uniquement avec les mesures disponibles avant
date d'alerte + 4 h. - Fenêtres historiques : 3, 7, 14 et 30 jours ; niveaux, dispersion, tendances, persistance critical et écart à la normale propre à l'appareil.
- Chaque visite devient un échantillon décrit par 86 variables numériques. Les 262 910 mesures servent à construire leur historique ; elles ne deviennent pas 262 910 exemples étiquetés.
- Validation principale : cinq plis gardant chaque campagne entière hors entraînement.
- Stress test : cinq plis gardant chaque appareil entier hors entraînement.
- Combinaisons : moyenne non pondérée des rangs de deux ou trois modèles. Aucun poids optimisé sur ces 99 fuites.
Du fichier brut à un échantillon
262 910 mesures acoustiques
↓ historique disponible avant la visite
344 visites avec observation du technicien
↓ appareil relié + mesure du matin présente
320 échantillons utilisables = 99 fuites + 221 non-fuites
↓ séparation par campagne ou par appareil
entraînement sur 4 groupes / évaluation sur le 5e groupe jamais vu
La cible label vaut 1 quand l'observation du technicien confirme une fuite et 0 dans les autres visites. Un appareil jamais visité n'est jamais transformé en faux exemple négatif.
Résumé descriptif des échantillons réellement utilisés :
| Classe | Échantillons | Minimal récent médian | Anomalie médiane | Part critical sur 7 j médiane |
|---|---|---|---|---|
| Pas de fuite | 221 | 466 | 0.52 | 1.00 |
| Fuite confirmée | 99 | 601 | 1.09 | 1.00 |
Ces médianes décrivent les groupes ; elles ne constituent pas une règle de décision.
Comment lire les noms des variables
Un nom comme minimal_mean_7d se décompose ainsi :
minimal,frequency,spread: les trois valeurs acoustiques exportées par SEPEM ;latest: dernière valeur disponible avant la limite de 4 h ;3d,7d,14d,30d: fenêtre de 3, 7, 14 ou 30 jours ;mean/median: moyenne / médiane de la fenêtre ;std/range: variabilité / écart entre minimum et maximum ;delta: dernière valeur moins la première ;slope: tendance générale, positive si la mesure augmente ;critical_ratio_7d: part des mesures des sept derniers jours au-dessus du seuil critical ;minimal_device_robust_z: écart entre la dernière mesure et la normale propre à cet appareil. Une valeur élevée signifie « inhabituel pour ce capteur ».
Les identifiants d'appareil, les dates et les observations textuelles ne sont pas donnés au modèle comme raccourcis de prédiction.
Modèles comparés, en langage courant
| Nom affiché | Idée simple | Rôle dans le benchmark |
|---|---|---|
vendor_minimal |
Classe selon le niveau acoustique récent, comme la logique fournisseur actuelle | Référence à battre |
device_anomaly |
Cherche un changement inhabituel par rapport à l'historique du même appareil | Signal personnalisé sans apprentissage des étiquettes |
logistic_l2 |
Additionne les indices avec des poids limités pour éviter les décisions extrêmes | Modèle stable et explicable |
logistic_l1 |
Variante qui force beaucoup de variables inutiles à avoir un poids nul | Sélection automatique de variables |
svm_rbf |
Trace une frontière courbe entre fuites et non-fuites | Teste des séparations non linéaires |
random_forest |
Fait voter plusieurs arbres construits sur des sous-échantillons | Capture des règles et interactions non linéaires |
extra_trees |
Fait voter des arbres encore plus randomisés | Réduit la dépendance à une seule règle fragile |
hist_gradient |
Corrige progressivement les erreurs d'une suite de petits arbres | Modèle de boosting intégré à scikit-learn |
xgboost |
Boosting régularisé, populaire sur les données tabulaires | Concurrent plus flexible, mais plus exposé au surapprentissage |
isolation_forest |
Repère les visites rares sans utiliser l'étiquette fuite/non-fuite | Référence non supervisée |
COMBO |
Fait la moyenne des rangs produits par plusieurs signaux | Cherche un accord entre méthodes différentes |
Le combo ne vote pas « fuite / pas fuite ». Chaque composant attribue un score, les visites sont classées, puis leurs positions moyennes donnent le classement final.
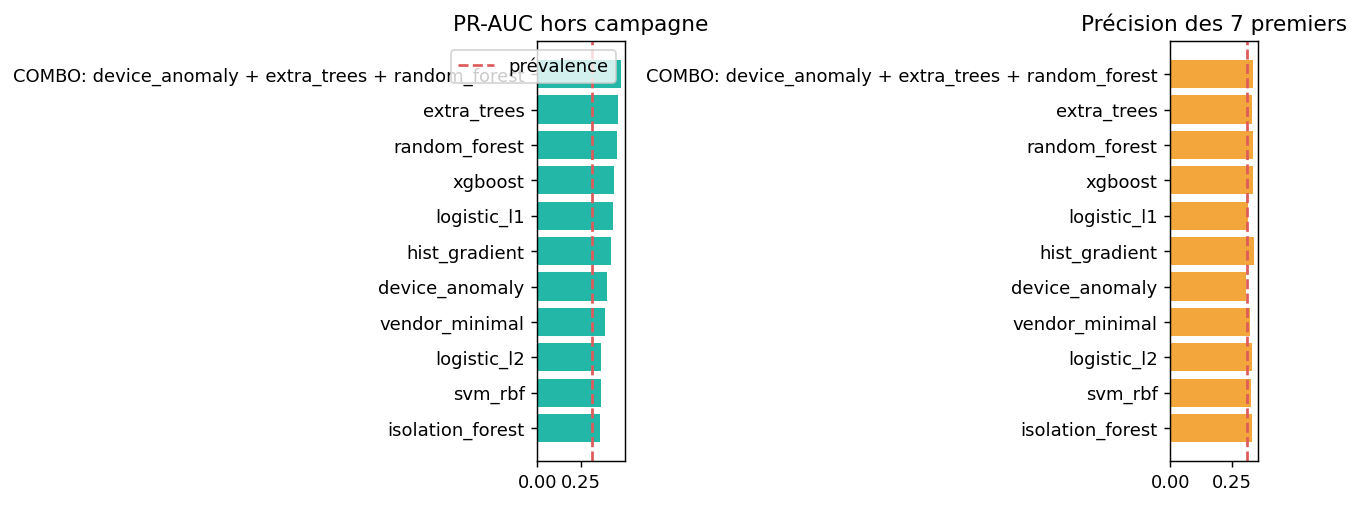
Validation sur campagnes inconnues
| Modèle | PR-AUC | ROC-AUC | Précision@7 | Rappel@7 |
|---|---|---|---|---|
| COMBO: device_anomaly + extra_trees + random_forest | 0.475 | 0.674 | 0.333 | 0.828 |
| extra_trees | 0.457 | 0.676 | 0.329 | 0.818 |
| random_forest | 0.455 | 0.663 | 0.333 | 0.828 |
| xgboost | 0.438 | 0.636 | 0.333 | 0.828 |
| logistic_l1 | 0.433 | 0.636 | 0.313 | 0.778 |
| hist_gradient | 0.417 | 0.618 | 0.337 | 0.838 |
| device_anomaly | 0.399 | 0.596 | 0.305 | 0.758 |
| vendor_minimal | 0.387 | 0.586 | 0.321 | 0.798 |
| logistic_l2 | 0.364 | 0.580 | 0.329 | 0.818 |
| svm_rbf | 0.364 | 0.584 | 0.325 | 0.808 |
| isolation_forest | 0.355 | 0.559 | 0.329 | 0.818 |
Validation sur appareils inconnus
| Modèle | PR-AUC | ROC-AUC | Précision@7 | Rappel@7 |
|---|---|---|---|---|
| COMBO: device_anomaly + extra_trees + random_forest | 0.493 | 0.695 | 0.329 | 0.818 |
| random_forest | 0.462 | 0.694 | 0.337 | 0.838 |
| extra_trees | 0.456 | 0.689 | 0.333 | 0.828 |
| logistic_l1 | 0.450 | 0.632 | 0.317 | 0.788 |
| xgboost | 0.449 | 0.668 | 0.341 | 0.848 |
| hist_gradient | 0.439 | 0.659 | 0.333 | 0.828 |
| device_anomaly | 0.399 | 0.596 | 0.305 | 0.758 |
| vendor_minimal | 0.387 | 0.586 | 0.321 | 0.798 |
| svm_rbf | 0.374 | 0.586 | 0.313 | 0.778 |
| logistic_l2 | 0.370 | 0.558 | 0.305 | 0.758 |
| isolation_forest | 0.359 | 0.553 | 0.321 | 0.798 |
Comment lire les métriques
- PR-AUC : qualité globale du classement quand les fuites sont rares. La référence aléatoire est ici la proportion de fuites, soit 0.309.
- ROC-AUC : probabilité qu'une fuite choisie au hasard soit classée avant une non-fuite. Utile, mais parfois trop optimiste lorsque la classe positive est rare.
- Précision@7 : parmi les sept premières visites proposées dans chaque campagne, part de vraies fuites.
- Rappel@7 : part de toutes les fuites connues qui se trouvent dans ces sélections de sept visites.
- Hors campagne : aucune visite de la campagne testée n'a servi à entraîner le modèle.
- Hors appareil : aucune visite de l'appareil testé n'a servi à entraîner le modèle ; c'est le contrôle le plus strict contre la mémorisation d'un capteur.
Les prédictions sont dites out-of-fold : chaque score affiché a été produit par un modèle qui n'avait pas vu cet échantillon pendant son entraînement.
Meilleure combinaison
device_anomaly + extra_trees + random_forest
- PR-AUC hors campagne : 0.475 ; précision@7 : 0.333.
- PR-AUC hors appareil : 0.493 ; précision@7 : 0.329.
- Test chronologique à partir du 2025-10-17 : PR-AUC 0.618, précision@7 0.366, rappel@7 0.839.
- Prévalence des fuites : 0.309. La PR-AUC hors campagne atteint 1.54 fois cette référence, mais le gain à sept visites reste faible.
Pour une politique strictement limitée aux sept premiers, le signal le plus stable est hist_gradient (précision@7 minimale 0.333 entre les deux validations). Beaucoup de campagnes ne contiennent qu'environ huit visites : sélectionner sept lignes laisse mécaniquement peu de marge au modèle.
Interprétation correcte
Ce benchmark classe des visites historiques déjà sélectionnées. Il ne mesure pas le rappel sur les 443 appareils, car les appareils non visités sont non étiquetés. La meilleure combinaison est une hypothèse de pilote, pas une preuve de déploiement.
Le prochain test utile est prospectif : utiliser le classement pour sept visites et conserver une huitième visite d'audit hors classement. C'est cette collecte qui permettra de mesurer le gain réel et le biais de sélection.
Les résultats complets sont disponibles dans model_benchmark.csv.